

Sommaire
Le projet Data&Musée collecte un ensemble de données qui concernent Paris Musées.
Cette page donne une description générale de ces données avec éventuellement des liens vers un accès aux données et un lien vers une page de description plus précise des données.
Les données ne sont pas toutes disponibles publiquement.
Liste des membres de Paris Musées et données associées
FPM1: une liste des musées de Paris Musées a été établie. Il s’agit d’un fichier JSON qui contient aussi les liens éventuels vers des entités décrites dans DBPedia, DBPedia-fr ou Wikidata. On notera que certains musées ne semblent connus d’aucune de ces trois bases de connaissances (ces liens ont été établis de façon semi-manuelle par une recherche automatique avec vérification humaine, puis recherche manuelle pour les musées n’ayant aucun résultat; certains liens ont pu échapper au processus).
Le fichier est ici:
Lien privé: https://ws49-cl4-nextcloud.tl.teralab-datascience.fr/index.php/s/zaSn7CmAQ7iXFSH
Données de Livres d’Or
Des données de livre d’or électronique sont accessibles à partir de 2016 (pour les partenaires du projet). Les données de 2019 n’ont pas encore été observées.
Pour 2018, nous avons les éléments suivants:
| 2016 | 2017 | 2018 | Total | |
|---|---|---|---|---|
| Contributions | 1450 (1374-fr; 76-en) | 8017 (7114-fr; 817-en; 86-es) | 27644 | 37111 |
| avec origine géographique | 11734 |
Exemple de présentation: contributions par semaine
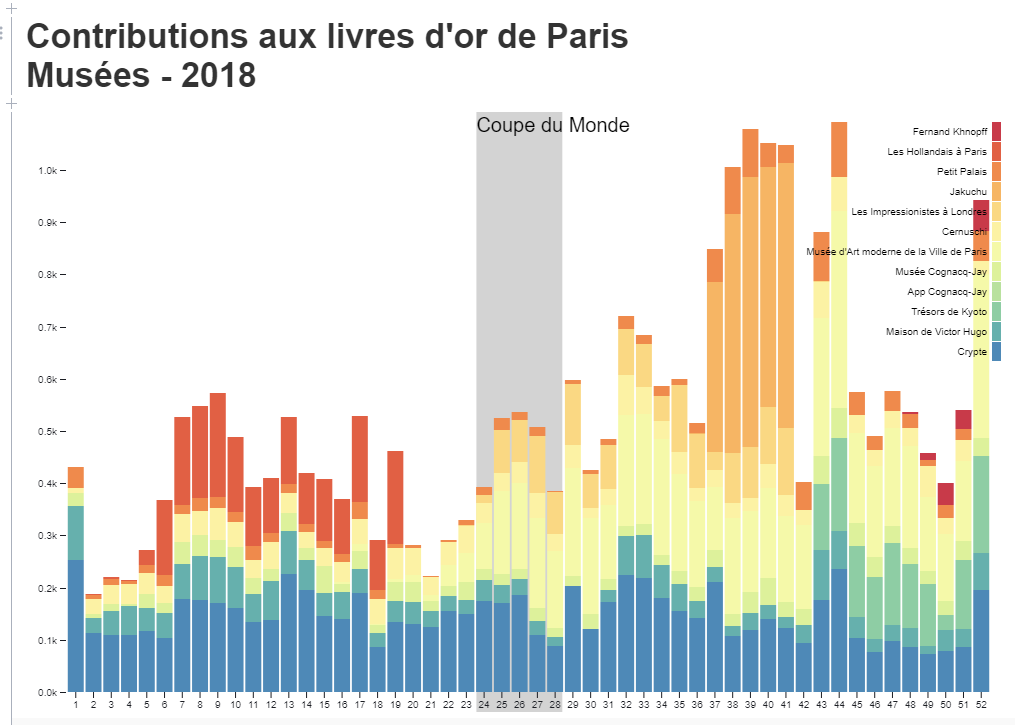
Voir Données de Guestviews
__________________________________________________________________________________
Liens avec le Web des Données (LOD)
Voir Données du LOD
__________________________________________________________________________________
Données de billetterie
A partir du 11/2/2019, un fichier de données de billetterie pour la semaine écoulé est déposé chaque semaine sur NextCloud dans le dossier
/Sources/SourceParisMusées/Data Billetterie Paris Musées
Il y a un dossier créé lors de chaque dépôt qui contient un fichier zip d’environ 4 Mo, représentant environ 50 Mo une fois décompressé. Les données sont au format csv avec séparateur ; et première ligne composée des entêtes de colonnes. Le codage est Unicode (UTF-8). Un fichier comporte de l’ordre de 130000 lignes.
A vérifier: il semble que le fichier cumule les données à partir du 23/1/2019, avec 15000 à 20000 nouvelles lignes chaque semaine. Dans cette hypothèse, on aurait environ 5 Mo décompressés chaque semaine, soit environ 300 Mo sur l’année.
L’interprétation des colonnes doit être documentée. Par exemple, la colonne R a pour entête TARIF_PLACE_TTC et, hors la valeur 0, des valeurs exprimées en centaines: s’agit-il bien de centimes d’euros? La colonne BT (PRENOM_CONTACT_CULTUREL) correspond à quoi?